
Building Kubernetes Operators : Understanding the API
Understanding the API is the first step in the process of building Kubernetes Operators.


In the next 12 minutes, you will gain the pre-requisite knowledge needed to create your own Custom Resource Definitions. You will also develop a different image of the working of Kunernetes and how to look at it as a Developer rather than a User.
This is the first article of a series "Building Custom Kubernetes Operators", where we will start from ground zero to end with creating a custom operator.
Why Build an Operator
A custom resource + the controller is called an operator. Kubernetes operators extend the cluster's behavior without modifying the code of Kubernetes itself by linking controllers to one or more custom resources. Adding new features in the main Kubernetes Repository is a long task that needs a lot of reviews, discussions etc. It might not be needed by other organizations using Kubernetes, so an organization can build an operator, that adds new features to their Kubernetes Cluster and not the main Kubernetes code base.
To extend the behavior of anything, it is very important to understand how that thing works, that is what this article is for.
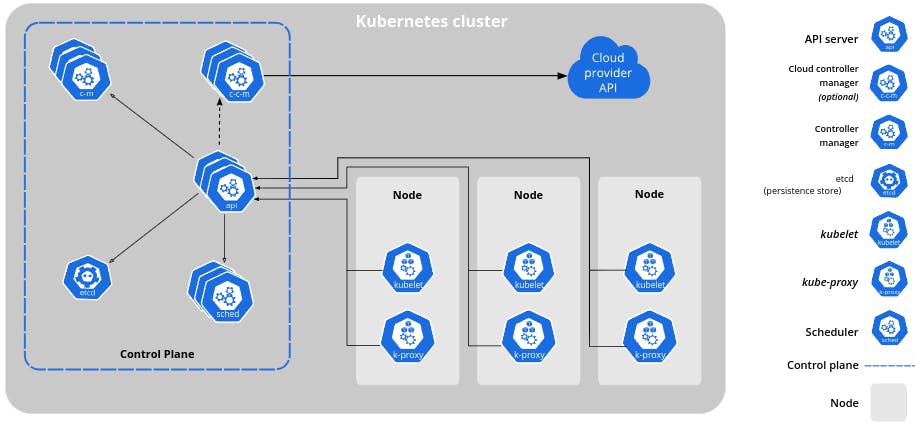
What is Kubernetes
A lot of things must come to your mind when you hear the word Kubernetes, but at the end of the day, it is software, written in a programming language (Go) and following certain principles so that things are consistent with every update.
When I call it software, you might think of it as a single binary, like the Visual Studio Code application, but it is a little different, instead, it is a collection of binaries, which are available as images that can be run inside a container runtime (Fancy word for an application that provides an environment to run the images).
See this Download Kubernetes, you can see a list of Container Images and their supported architectures. All these Container images are individual components, that together make the Kubernetes cluster (Remember the architecture ?). You will most probably need one more binary called Kubectl which is a command line utility, that is used to interact with the Kubernetes cluster.
From a mile's distance, think of Kubernetes as just an application that is running/orchestrating your applications, Zoom in a bit, and now you can see it as a cluster, with different components working together to make it a Container Orchestration Engine.
What Kubernetes does
Kubernetes is a platform, that provides many pre-developed, battle-tested features that help you in managing your application's lifecycle, where lifecycle includes Creation, Management and Deletion. These pre-configured Building blocks are Resources, Controllers, Pods, Deployment, Service etc. The list goes on. But these are small pieces, that provide some functionality, which you can use directly instead of building from scratch.
For example, To run an application/process in the cluster, you can run a pod with the app's image, just provide the image and instruction to the API Server and it will run that application. A comparatively bigger example use case will be, when you have an application that you want to be always running, doesn't matter if something fails, and the ability to easily up/downscale them, You can use a deployment, which is yet another building block of Kubernetes itself. Just create a deployment of the application and provide it to the API Server (your work is done), It will create a ReplicaSet, which in turn will create pods. If pods fail, it will restart them as well.
From now on, we will call these Building Blocks Resources.
Resources and Controllers
Alternatively, you can imagine the working of Kubernetes as a combined effort of Controllers and Resources. Resources are things like Pods and Controllers are loops that manage them (Creating, Updating and Deleting). So, let's take an example of Deployments, this workflow will help you understand things better.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: nginx:latest
Consider the above deployment, when that is applied to the cluster using `kubectl apply -f deployment.yaml` the following things happen.
API server receives the object and validates the syntax, if it is valid, it will create or update the Deployment object in the etcd datastore.
The Deployment controller watches all the changes happening with Deployment objects in the etcd datastore and gets triggered. The controller then creates corresponding replica sets. A replica set for the above deployment will look like this.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: my-deployment-1234567890 # An automatically generated name
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: nginx:latest
The Job of Replica sets is to ensure that the same number of pods, as mentioned in the Deployment (that created the replica set), are always running. How does that work? The Replica Set controller.
The Replica Set controller watches the Replica sets and ensures the actual number of running pods is the same as mentioned in the Replica Sets.
This pattern can be seen in a lot of places inside Kubernetes, for the Services we have the Service Controller etc. There might be questions regarding how these controllers know if something they care about (their respective objects) has changed. Informers are core concepts that do that, we will talk about them later.
Now we know, that Kubernetes is a platform, that contains these core building blocks (Resources and their controllers), that provide different functionalities that we can be used to orchestrate our applications. But it is highly extensible, we can create our Resources and Controllers, which will be an extended/additional building block of the platform.
So, if Kubernetes has let's say 10 core blocks (Resources like Pods, Deployments etc.), pre-configured with a specific version, an organization can take those, add one (or many) of their blocks, and make it 11 (or more) hence making it a platform for their personal needs. This process is called Extending the Kubernetes API. But before we learn how to extend the API, let's get more familiar with concepts like Resources and Controllers
Kubernetes API (Server)
Just like any other API, Kubernetes API is the Interface through which you can access some "Functionality" of the cluster. Just like this Cat facts API, where you can do a GET request, and it will return a random fact about cats. Interactions with the Kubernetes API perform the same results, instead of cats, it does things to the Kubernetes Cluster it belongs to.
For a newcomer, there are fewer chances that they have interacted with their Kubernetes cluster using the API server "Directly" and have used Kubectl instead. That directly is bold for a reason, the fact is, every interaction with the cluster is done via the API Server. Kubectl for instance, is just a utility, that helps in making that interaction with the API server easier, Under the hood, it is doing the same thing i.e. HTTP requests to the server.
Kubectl under the hood
when you run kubectl get pods -n kube-system on the terminal, It returns the list of pods that are running on the cluster, inside the kube-system namespace.
➜ ~ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-5d78c9869d-cgwjg 1/1 Running 0 53s
coredns-5d78c9869d-glh7s 1/1 Running 0 53s
etcd-b-control-plane 1/1 Running 0 68s
kindnet-7rfnf 1/1 Running 0 53s
kube-apiserver-b-control-plane 1/1 Running 0 68s
kube-controller-manager-b-control-plane 1/1 Running 0 68s
kube-proxy-fftxp 1/1 Running 0 53s
kube-scheduler-b-control-plane 1/1 Running 0 68s
Now, let's see what happens under the hood, run kubectl get pods -n kube-system --v=6
➜ ~ kubectl get pods -n kube-system --v=6
I0912 16:01:01.167599 344582 loader.go:373] Config loaded from file: /home/prateek/.kube/config
I0912 16:01:01.177157 344582 round_trippers.go:553] GET https://127.0.0.1:43877/api/v1/namespaces/kube-system/pods?limit=500 200 OK in 6 milliseconds
NAME READY STATUS RESTARTS AGE
coredns-5d78c9869d-cgwjg 1/1 Running 0 11m
coredns-5d78c9869d-glh7s 1/1 Running 0 11m
etcd-b-control-plane 1/1 Running 0 12m
kindnet-7rfnf 1/1 Running 0 11m
kube-apiserver-b-control-plane 1/1 Running 0 12m
kube-controller-manager-b-control-plane 1/1 Running 0 12m
kube-proxy-fftxp 1/1 Running 0 11m
kube-scheduler-b-control-plane 1/1 Running 0 12m
There will be two additional lines on the terminal this time. Look carefully at the second line, there is a GET HTTP request to the URL https://127.0.0.1:43877/api/v1/namespaces/kube-system/pods.
The --v=6 flag is used to increase the verbosity of logs generated by Kubectl. The second line in the logs clearly shows that Kubectl made an HTTP request to that URL. Let's try to understand that URL now, through this, Kubernetes concepts like Group Version Kind and Group Version Resource can be understood.
https://127.0.0.1:43877/: It is the address (IP address and Port number) at which the Kubernetes API server is listening, Anything that is done with the cluster through Kubectl, will eventually be converted into a URL and sent to this address./v1: This tells the specific API version being used, Yes there are multiple API versions in Kubernetes for which you can read this./namespaces/kube-systm: Is used to specify that the resources are to be checked in a specific namespace, that namespace being kube-system./pods: This is specifying the Resource that is being interacted with.
Combining line number two says, "Kubernetes API server listening on https://127.0.0.1:43877/ GET me all the /pods in the kube-system namespace". Now let's understand the additional stuff mentioned.
Groups, Versions, Kinds and Resources
This is a simplified version of this concept, the amount needed to understand how to extend the Kubernetes API. I will write more in-depth blogs with increasing understanding.
Kubernetes is very Flexible and has evolved over the years. Every resource in Kubernetes is present in a Group, Grouping is done to make the maintenance of these resources easier and we use /api for core group and /apis for non-core groups in the URL to interact with the API server.
The same goes for their Versions, there are four versions when it comes to Kubernetes resources, v1, v1alpha1, v1beta1 and deprecated. Whenever a new feature is introduced, it starts with v1alpha1 "alpha phase", because it is still not fully battle-tested, not ready for production and looking for User feedback. It can undergo significant changes between multiple releases.
As the feature gets improved, it becomes relatively stable and enters the v1beta1, still not ready for production but the changes in future releases are not ground-breaking. It is more thoroughly tested in real-world examples and improved. Finally, it enters the "stable" phase, version v1. It is now ready to be used in production and has a well-defined and stable API. These resources are Backward compatible with future releases. Similar dynamics are used when depreciating a feature, that brings to light the deprecated phase.
Now the final part, Kinds and Resources. They are familiar sounding but different. To some extent, you can think of Kinds as classes and Resources as objects of that type.
Kind is a field in the Kubernetes manifest, it tells the API about the type of object being interacted with. Resources are used in the context of the API URLs, like in the above URL, "pods" are being interacted with, and they are resources of type Pod. So, we use resources to interact with the API and not kinds, because Kinds do not exist in the cluster, instead they are concepts, that are used to define functionality. A pod kind is used to run a process, a service kind can be used to enable network communication etc. but to materialise them, a resource of that kind needs to be created.
Summary so far
Up till now, we understood the following:
API server and URLs: The Kubernetes API server is the core component for managing and interacting with the cluster. API requests are made using URLs structured as
<api-server-address>/api/<Group>/<Version>/namespaces/<Namespace>/resource.URL Components:
<api-server-address>: The address of the Kubernetes API server.<Group>: The API group, is used to categorize the resources for easier management.<Version>: The API version, defining the API schema (allowed features for that version), where different schema can have the same resources providing different and more stable functionalities.<namespaces/Namespace>: Optional, used to tell that the resources should be looked for in a specific namespace.<resource>: The specific resource type you want to interact with.Examples: To get all the pods in the
hellonamespace, the URL used will behttps://<api-server-address>/api/v1/namespaces/hello/podsand to get deployments in thedefaultnamespace, the URL for the GET method will be
https://<api-server-address>/apis/apps/v1/namespaces/default/deployments.
Controllers
Controllers are the loops that are responsible for implementing "what to do when a certain thing changes in the cluster". They are configured to watch for changes in a specific Resource (e.g.: Deployment Resource) and do something when the change happens (e.g.: Create Replica set resources). The developer writing the controller is responsible for deciding what the controller does when triggered.
Example: For this Deployment, we have this Deployment Controller. Now, most of the code might not be understood (yet) but that Deployment struct is used to define what the deployment resource would look like, and the controller is responsible for Creating, Updating, Deleting Deployments, also responsible for tasks like Creating Replica Sets and so on. All it knows is, "Something happened with the Deployment of this Name in this Namespace" and it contains logic to check what happened, and also how to reflect the changes in the Replica set objects. Where the changes in Replica Sets are watched by the Replica Set controller.
They don't need a custom resource, they can watch any resource present inside the cluster (if they have properly configured RBAC), and get triggered when the resource changes. So, in later stages, when we extend our platform (Kubernetes), we create a new controller, and if needed, we also create a new Custom Resource (and a controller for it).
Thorough understanding can be gained by building an operator, this article is just setting up the ground.
Extending the Kubernetes API
In simple words, it's all about creating a new Resource, the controller managing it and registering it to the API schema. To create a new block for the platform, four things are needed, a new Group, a Version (start with v1alpha1), a Kind (choose a name) and a Controller to implement the Business logic related to that Resource. Various tools like Kubebuilder help make these tasks easier, but eventually, the Go Controller Runtime package is the core, everything else is built on top of it.
Ending Remarks
In the upcoming blogs, we will understand these packages in-depth, where amazing concepts like Managers, Reconciling Loops etc. will be introduced. Kubebuilder Book is one of the best resources so far, I learned to create my first controller from it.
I am an engineering undergrad, in my final year, and I learned everything about building a Custom Operator in almost 4 months, where I worked as an LFX mentee under the Cilium Project. I am writing a separate blog about my experiences, but I encourage every student to be a part of it.
Upcoming articles will contain a detailed guide to how I created the PodInfo custom resource for the Tetragon Project, a sub-project of the Cilium Project in my internship.
Till then, I would recommend these resources to strengthen your ground for further articles:
Kubernetes API Fundamentals by KodeKloud, is an amazing resource.
Kubebuilder Book is one stop, for entire operator creation, to testing.