Introduction to eBPF
Discover how eBPF allows developers to safely extend Linux kernel capabilities for observability, tracing, and security.

I am a Full stack Software engineer, majoring in Computer science. I have strong foundational skills in multiple domains including Frontend, Backend engineering as well as Kubernetes administration. I am an active Open Source contributor, with contributions in major Open source projects including Cilium, Dapr etc. I also love to build products in general so I am trying out new tech regularly. I am also founder of Senseii, a SaaS product that helps people in their fitness journey by creating workout and meal plans for them. It also helps them follow their plan by regular updates and real time data processing.
What is eBPF
Taken from the book Learning eBPF, by Liz Rice, “eBPF allows developers to write custom code that can be loaded into the kernel dynamically, changing the way the kernel behaves.”
To fully grasp this concept, it's essential to first understand a few key elements. Let's break them down one by one.
Kernel Space vs User Space
The Linux kernel is the core part of the Linux operating system. It acts like a bridge between the hardware (like your computer's memory, processor, and devices) and the software (your apps and programs). It manages resources and ensures different tasks work smoothly without interfering with each other.
Applications run in an unprivileged layer called the user space, which is not allowed to access hardware directly. Instead these applications make requests to the kernel using the system call interface, for it to act on the application’s behalf.
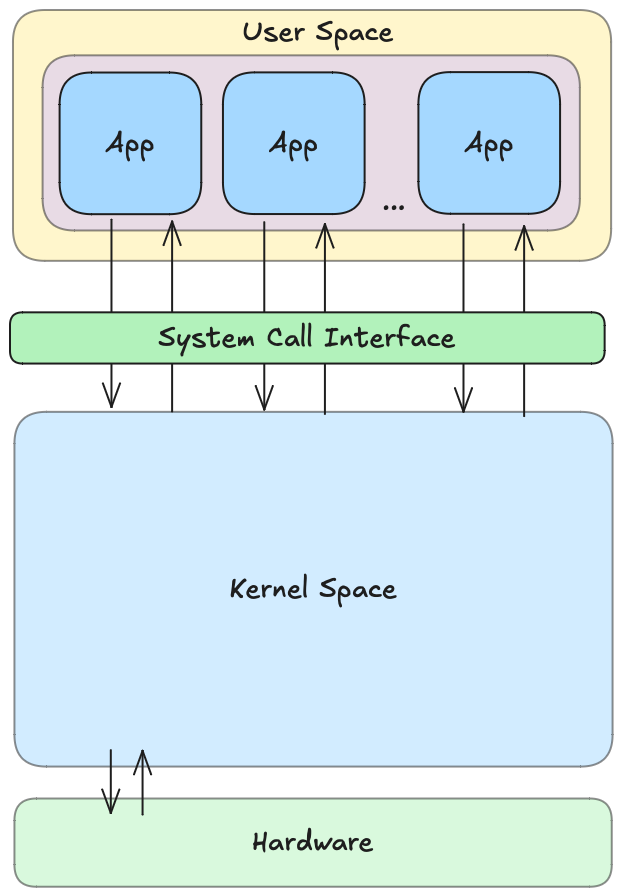
let’s take an example where you double click on a file to open it.
Interaction: You click on the file to open it. The program (like a pdf file reader) sends a request (open() system call) to the kernel to access the file.
Permission check: The kernel checks if you have the required permissions (read/write etc.) to access the file.
Hardware communication: If the permission check passes, the kernel talks to the hard drive, to locate and fetch the file data you requested.
Loading data: The kernel loads the file data into the computer’s memory (RAM) so that the pdf reader can access it.
Program opens the file: The file opens in your file reader, and you can start reading or editing it.
Kernel Space has Superpowers
Since the kernel operates with the highest privileges and has complete control over system resources, it's an ideal place for tasks like:
System Observability
Performance tracing hardware and software interactions
Highly configurable network operations
Enforcing security policies and preventing unauthorised actions (system calls)
By running programs in the kernel space, we have access to system wide observability without the limitations of user-space applications.
Programs in Kernel Space
There are different ways you can run custom logic in kernel space depending upon the use cases and how deeply you want the program to integrate with the kernel. Some of the ways are listed below with very brief introductions.
1. Kernel Modules (Loadable Kernel Modules or LKMs):
What it is: A kernel module is a piece of code that can be dynamically loaded into the kernel without needing to modify the entire kernel or reboot the system. You can unload them when no longer needed.
Use case: Common for adding features like device drivers, filesystems, or custom kernel logic.
Example: Writing a module to intercept system calls or manage custom hardware drivers.
| Pros | Cons |
| loadable and un-loadable without needing to reboot the system., well-supported, ideal for device drivers. | Requires kernel knowledge, can cause crashes, needs maintenance for version compatibility. |
2. Modifying the Kernel Source (Adding a Program via a Kernel Patch):
What it is: Directly modifying the kernel source code to integrate your logic and submitting it as a patch (Pull Request) to the kernel.
Use case: If you need deep integration into the kernel or want your changes to be permanent and distributed as part of the official Linux kernel.
Example: Adding a new system call or modifying existing kernel behaviour.
| Pros | Cons |
| Full control, ideal for deep integrations, can be merged upstream. | Requires kernel recompilation, can be unstable, maintenance-heavy, hard to distribute, time consuming, patch might not get approved. |
3. Using Kernel Hooks:
What it is: Some parts of the kernel provide "hooks" or extension points, where custom logic can be attached. These are predefined places where you can plug in custom logic without modifying the kernel itself.
Use case: Good for extending kernel functionality in specific areas like the scheduler, network stack, or security subsystems.
Example: Using Netfilter hooks to intercept and modify network traffic.
| Pros | Cons |
| Clean extension points, supported in specific subsystems, tested, more safe. | Limited by hook availability, limited configuration, misuse can cause instability. |
4. System Tap and DTrace:
What it is: These are tools that allow dynamic insertion of instrumentation points into a running kernel. While not adding logic per se, they let you observe and trace kernel activity without modifying the kernel code.
Use case: Mostly for system profiling, debugging, and observability.
Example: Monitoring CPU usage, memory allocation, or I/O activity in real time.
| Pros | Cons |
| Easy to trace kernel events, minimal performance impact, no kernel modification needed. | Limited to monitoring/tracing, requires elevated permissions, not for custom Kernel logic, and some platform limitations. |
5. eBPF (Extended Berkeley Packet Filter):
What it is: eBPF is a powerful, safe mechanism for running sandboxed programs inside the Linux kernel without modifying the kernel source or adding a module. eBPF programs can be dynamically loaded and are verified for safety.
Use case: Ideal for observability, tracing, networking, and security-related logic. You can trace system calls, network packets, or even specific kernel functions, all in a highly efficient and secure way.
Example: Using eBPF to trace performance bottlenecks in an application or monitor network traffic at the packet level without adding a kernel module.
Focus on eBPF:
eBPF is a standout option because it allows running custom logic in kernel space safely and efficiently, without needing to modify the kernel or load heavy modules. It has grown to support not only network tracing but also system performance monitoring, security filtering, and even application tracing—making it one of the most versatile tools for kernel-level operations today. One of the biggest features include the ability to write code in high level languages like Go, Python etc. We will see that in the upcoming articles.
Connecting the dots
Now, if we go back to the first statement in the article, we understand that with eBPF we can write code in high level languages and run it in the privileged Kernel space, in a safe sandbox that ensures that the code you wrote doesn’t break the kernel.
This is the introductory article about what you need to know to fully appreciate what eBPF offers and how wide it’s use cases are, in the next articles, we will dive deeper and start writing eBPF code that runs.
In the meantime, if you want more examples and are a visual learner, go through the following resources:




